The L-BAM library comprises information about pre-trained models,
including information about where they are located online so that they
can be automatically downloaded in R. The models are continuously being
tested using GitHub actions, and you can checkout the code for running
each model here.
The models can be called with textPredict(),
textAssess() or textClassify() like this:
library(text)
# Example calling a model using the URL
textPredict(
model_info = "valence_facebook_mxbai23_eijsbroek2024",
texts = "what is the valence of this text?"
)
# Example calling a model having an abbreviation
textClassify(
model_info = "implicitpower_roberta23_nilsson2024",
texts = "It looks like they have problems collaborating."
)The text prediction functions can be given a model and a text, and automatically transform the text to word embeddings and produce estimated scores or probabilities.
Important: Language-based assessments can be developed in one context—such as social media—and applied in another—like clinical interviews. However, models don’t always generalize across settings. A model’s performance depends on several factors, including the context in which it was trained, the population, the distribution of the psychological outcome, and the language domain (i.e., how similar the language in the training data is to the new data).
Because of this, users are responsible for evaluating whether a model is appropriate for their specific use case. This means checking whether the training and evaluation conditions align with their own data—and, if needed, validating the model’s performance on a subset of their own data before making any conclusions. That’s why each model in the L-BAM Library comes with detailed documentation on its training data, performance metrics, and development process. Transparent documentation helps users make informed decisions and supports reproducible, trustworthy research (for more information see Nilsson et al., in progress).
If you want to add a pre-trained model to the L-BAM library, please fill out the details in this Google sheet and email us (oscar [ d_o t] kjell [a _ t] psy [DOT] lu [d_o_t]se) so that we can update the table online.
Note that you can adjust the width of the columns when scrolling the table.
Overview of L-BAM pipelines
Training and using models from the L-BAM library involves three key steps. First, written language is turned into numerical formats known as word embeddings using a large language model (Figure 1A). Next, these embeddings are used to build a predictive model linked to a specific outcome or assessment target (Figure 1B). Finally, the trained model can be applied to new texts for evaluation or classification purposes (Figure 1C).
You can find a detailed guide on how to transform language into
embeddings and train L-BAMs using the text package in Kjell et
al. (2023). Below, we briefly introduce the embedding and training
process before showing how to apply models from the L-BAM library. 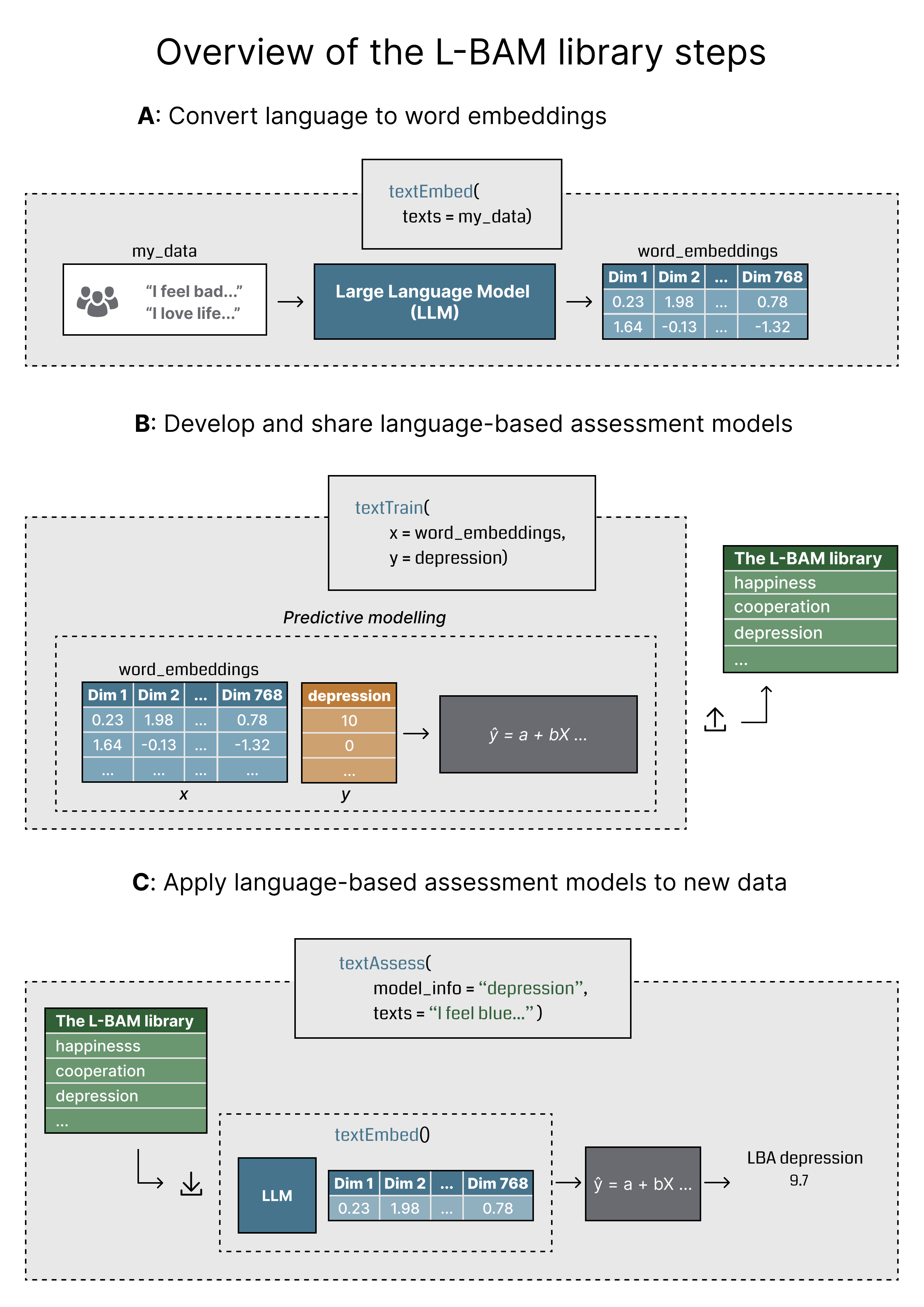
Figure from Nilsson et al. (in progress).
References
Gu, Kjell, Schwartz & Kjell. (2024). Natural Language Response Formats for Assessing Depression and Worry with Large Language Models: A Sequential Evaluation with Model Pre-registration.
Kjell, O. N., Sikström, S., Kjell, K., & Schwartz, H. A. (2022). Natural language analyzed with AI-based transformers predict traditional subjective well-being measures approaching the theoretical upper limits in accuracy. Scientific reports, 12(1), 3918.
Nilsson, Runge, Ganesan, Lövenstierne, Soni & Kjell (2024) Automatic Implicit Motives Codings are at Least as Accurate as Humans’ and 99% Faster